初めてのレコメンドエンジン Jupyter notebookでサンプルを動かそう

PythonのAnacondaというパッケージを使ってシンプルなレコメンドエンジンを動かすことができる。ローカルマシンにインストールしてもいいし、もちろんサーバーにインストールすることもできる。Pythonの書き方が分かれば、目的や用途に応じてかなり幅広いことができる。この記事ではAnacondaに含まれるjupyter notebookを使ってレコメンドエンジンを動かすことに焦点をしぼってみる。
https://www.anaconda.com/download/
Anacondaを選ぶ理由は機械学習に便利なライブラリがセットになっており、もちろんPython本体も入っているからだ。numpyもscikitもpandasも個別にインストールする必要がなく、Anacondaだけインストールすればいい。これは楽ちんだ。
目次
- Anacondaをインストールする
- レコメンドエンジンを動かすサンプルのデータセットを入手する
- データの中身を見てみる
- Jupyter notebookでサンプルを動かす
Anacondaをインストールする
https://qiita.com/iamdaisuke/items/3671032a18f5c4bf37d1
Anacondaをインストールする方法についてはすでにまとめてある記事がネットにあるので、検索すればいくらでも出てくる。環境構築に関するネットの記事は先人の失敗談の宝庫で、本当にありがたい。参考にしてさくさく進めよう。なお、環境構築は繊細で面倒な作業だが、このインストールすら根気強くできないという人は、エンジニアに向いていない。
Anacondaのインストール後はバージョン確認をしておこう。この反応がないとインストールできていない。
conda 4.8.4
レコメンドエンジンを動かすサンプルのデータセットを入手する
自分でレコメンドエンジンを動かすデータを持っていれば問題ないが、最初はそもそもどういうデータが必要なのかすら分からないだろう。だからデータセットを使う。これまた幸いなことに、レコメンドエンジンを初めて動かす人のために素晴らしいデータセットを提供してくれるkaggleというデータ分析のコンペサイトがある。そこから学習者用のアニメデータをダウンロードしよう。rating.csvとanime.csvがそれだ。なお下記英語サイトからダウンロードには会員登録が必要である。
https://www.kaggle.com/CooperUnion/anime-recommendations-database
データの中身を見てみる
データを入手したら中身を見てみよう。こんな感じのCSVファイルだ。わざわざ説明するほどのものでもないが、それぞれのCSVのカラムの意味をまとめておく。
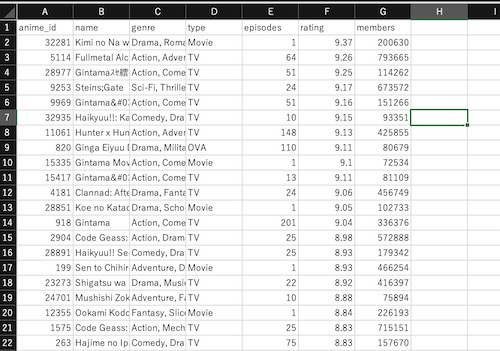
| カラム名 | 説明 |
|---|---|
| anime_id | アニメのID |
| name | アニメのタイトル |
| genre | アニメの属するカテゴリ |
| type | メディアタイプ(例:movie、tvなど) |
| episodes | 各アニメの話数 |
| rating | 1〜10(少数点含む)の平均レーティング(つまり評価) |
| members | 各アニメのを評価するユーザー数 |
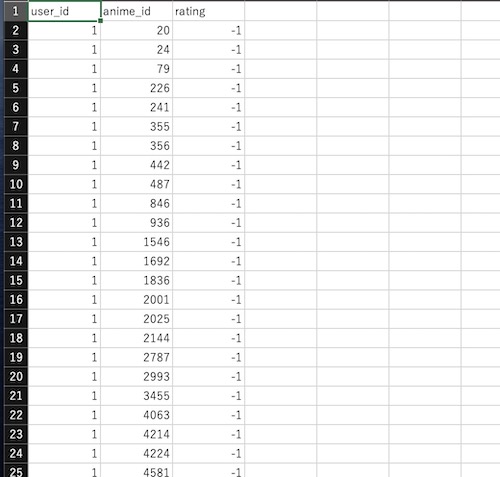
| カラム名 | 説明 |
|---|---|
| user_id | ユーザーID |
| anime_id | 当該ユーザーが評価したアニメID(うえのアニメIDと同じなのでkeyとして使う) |
| rating | ユーザーのそのアニメに対する評価 |
こういうデータがあればレコメンドエンジンを動かせると分かる。つまりウェブサイトやECサイトなどでレコメンドエンジンを動かすには、ブログ記事や商品に対するユーザーやお客さんの評価が必要となる。もちろんデータは多ければ多いほど精度が上がるのは言うまでもない。データをどのように用意するかはいったんおいておき、ここではサンプルを動かす件を前に進める。
Jupyter notebookでサンプルを動かす
Jupyter notebookである必要はないが、手っ取り早くPythonの動きを見るにはjupyter notebookは簡単でいい。もちろんAnacondaにも含まれている。
インポートするライブラリはコサイン類似度、K近傍の計算ができるcsr_matrixとNearestNeighborsだ。この辺りについて詳しくは情報推薦システムの知識が必要となるが、知らなくてもサンプルを動かすことくらいはできるが、アプリの実装は難しいかもしれない。本格的に勉強したい人は『情報推薦システム入門』を進める。なおこういう本にありがちだが、「入門」という言葉の持つ甘い響きに騙されてはいけないことは言うまでもない。

以下にjupyter notebookに入れるPythonのコードを紹介する。
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
#データの読み込み
ratings = pd.read_csv(‘rating.csv’)
anime = pd.read_csv(‘anime.csv’)
ratings.head()
anime.head()
Pandas
Pythonのライブラリであるpandasのdataframeを使いデータを読み込む。「Pandasって何?」という人がこの記事を読むことはないだろうが簡単に説明しておくと、ひと言で表現するならばエクセルで行うような集計をPythonで行うこと、がPandasの役割だ。大抵のビジネスマンなら業務でエクセルを使って面倒な集計などをしたことがあると思うが、まさにそういう集計をしてくれる。エクセルで解決するならエクセルでいいじゃん、と思うかもしれないが、何万行もに及ぶデータを扱う場合はpandasの効力を実感できるだろう。実際にこのアニメのデータセットでもPandasを使う意味がよく分かるとことだろう。
Pandasの他にもnumpy、mathplotlibなどPythonで数学やデータの集計を行うのによく使うライブラリがあり、これらについてまったく知らないという人は、関心があれば書籍などで概要をさらっておくといいかもしれない。『Pythonによるデータ分析の教科書』が関連する様々な情報の大まかな部分くらいは掴めるだろう。ただし、この本では深くは学べないと思うが。
データ処理は面倒くさい
続いてデータ処理に必要な下準備をする。世の中では「データ・サイエンティスト」なるちゃらい表現があり、開発現場の実態を知らない若い人を「データ・サイエンティストになるためのカリキュラム充実。これであなたも高収入」などのようにプログラミングスクールが宣伝しているが、そんな憧れるほどきれいな仕事ではない。現実のデータは離散的で、不整合で、扱うのが大変である。そういうデータを扱うには、面倒な下準備が必要なのだ。
このアニメのデータセットはサンプルなのできれいだが、それでも下準備は必要である。まして、実際にレコメンドエンジンを実装するとなると、自分でデータ設計をして、データを集めて、それを加工する作業が必要となる。要するに面倒くさいのだ。これからレコメンドエンジンを動かそうという人はこういう現実を必ず見据えておいたほうがいい。
Pandasのサンプルコード
anime_tv = anime[anime[“type”]==”TV”]
#anime_idをキーにして結合する
merge_data = rating.merge(anime_tv,left_on=”anime_id”,right_on=”anime_id”,suffixes=[“_user”,””])
merge_data.rename(columns={“rating_user”:”user_rating”},inplace=True)
#必要な3つのカラムのみ利用するよう絞る。空データはdropnaで削除
merge_data= merge_data.loc[:,[“user_id”,”name”,”user_rating”]]
merge_data = merge_data.dropna()
最終的にこういうデータが得られればレコメンドエンジンを利用できると分かる。つまり、どのユーザーがどのアニメをどう評価したか、である。いたってシンプルだ。
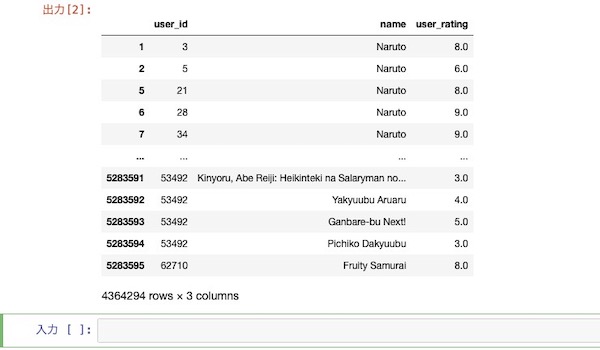
#ピボットテーブルでレーティングを整理まとめる
pivot_data = merge_data.pivot_table(index = [“user_id”],columns=[“name”],values=”user_rating”)
#疎行列の処理
pivot_sparse = csr_matrix(pivot_norm.values)
#コサイン類似度を求める
item_sim = cosine_similarity(pivot_sparse.T)
item_sim_data_frame = pd.DataFrame(item_sim,index=piv_norm.columns,columns=piv_norm.columns)
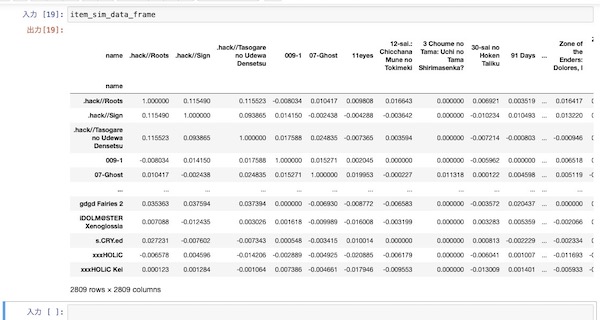
最後にコサイン類似度を求める箇所を関数にする。とりあえずここでは10件のレコメンドを求めることにする。
count=1
print(“{}を観た人にお勧めのアニメ:\n”.format(anime_name))
for item in item_sim_df.sort_values(by=anime_name,ascending=False).index[1:11]:
print(“No. {}: {}”.format(count,item))
count += 1
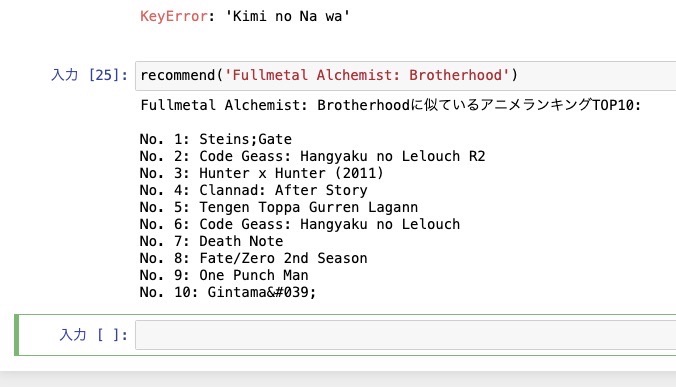
レコメンドエンジンのサンプルを動かす
ここまですれば、サンプルを動かせる。関数にアニメの名前を入れてみよう。なお上の写真の上部に「KeyError: ‘Kimi no Na wa’」とあるが、アニメ名は完全一致させる必要があるので要注意だ。サンプルのデータセットではアニメ名はアルファベット表記となっているが、仮に日本語データを扱う場合は全角の対応をしないといけない。これだけで一手間かかる。また、膨大なデータを扱う場合は処理に時間がかかったりする。それならばデータの呼び出しはIDをにすれば処理が楽になる。レコメンドエンジンを実装する際にはこういうところに気を回す必要がある。
どういう動きをするのか、どういうデータが必要なのか、どういう流れで処理をするのか感じは掴めたと思う。pandasとpythonが分かれば、原理的なレコメンドエンジンの部分はとりあえず動かせる。もっともこれを実装するとなると、まったく別の苦労や問題が発生するのだが、それまた次回紹介する。



